With all of the talk of “big data,” it can be hard to remember that there was ever any other kind of data. If you’re not talking about big data — you know, the 4 V’s: volume, variety, velocity, and veracity — you should go back to running your little science fair experiments until you’re ready to get serious. Prevalent though this message may be, it has, at least in health care, stunted our ability to focus on and capture the hidden 5th V of big data: value.
A thorny concept to be sure, the term “big data” has been used in so many different ways that it has become essentially synonymous with “emerging technologies in data science.” Deep learning, machine learning, artificial intelligence, self-service visualization, massive parallelization, high availability cloud computing, GPU clusters, NLP have all had their time in the sun as part of the du jour operational definition of “big data.” No doubt these are promising concepts and technologies, but in christening them with the “big data” label, we have given ourselves an unending string of distractions from the hard work of integrating data (of any size) into existing non-data processes and realizing their value.
Some of the most fun examples exist in health care. Who can forget Google Flu Trends, the Internet giant’s algorithmic campaign to use search traffic volume to predict flu outbreaks across the world 2 weeks before the best available methods? It took a few years, but as attention shifted elsewhere the predictions started to become wildly inaccurate and we were eventually made to relearn that most classic of lessons: garbage in, garbage out. We witnessed another big data fall from grace when Netflix shared that the one-million-dollar-movie-recommendation algorithm for which they had data scientists compete never made sense for them to implement. Admittedly, these are cherry-picked examples, but they illustrate important lessons that are often missed in big data implementations and may represent the visible tip of a much larger iceberg.
It is important to admit to ourselves, then, that we are on a stereotyped journey that has played out repeatedly in innovation. New buzzwords seasonally penetrate our shared consciousness and propagate like a virus or video on YouTube. The hype cycle popularized by Gartner describes the exhilarating rise and inevitable crash as our humanness allows us to overestimate the value of technology in the short term and underestimate its value in the long term.
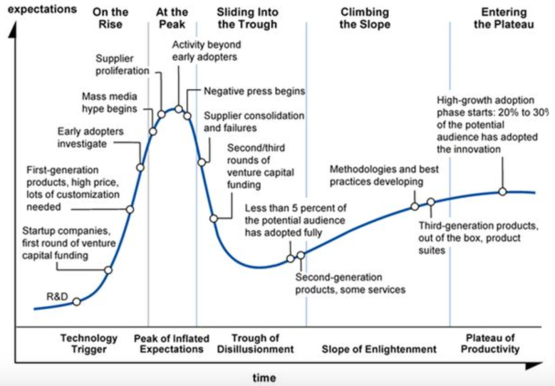
We can’t take all the blame, though. As long as there is excitement, there can be profit, and profit provides an engine that further stimulates the hype. The health care industry, in particular, has found itself awash in vendors peddling the latest data tech in order to bend the cost curve or adapt to the health care landscape that is so quickly shifting underfoot. Some products are actually useful! The trouble is there is so much froth and noise that it can be really, really difficult to know which ones they are. The signal of our peers’ purchasing decisions, the comfort of riding together to greatness or of misery with company becomes the basis for our own interactions with industry.
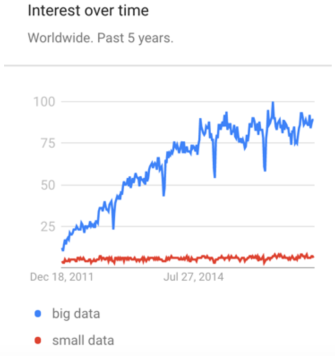
There is a solution to this today and it is to eschew the hype. It is to center oneself and focus finally on small data. Small data means driving towards lean processes, incremental infrastructure investments, and proven use cases. It is, in a word, the “Moneyball” of analytics. Oftentimes, the methods garnered by hype are well beyond what is needed and effective mainly in bloating a budget. Successful health care modeling efforts remind us that for most use cases, good ol’ regression gets you most of the way to the advanced machine learning method results. Perhaps the mantra of the small data movement is to humbly ask, “when is our small data big enough?”
In order to get there, we need to acknowledge that the true challenge before us remains not in squeezing every last mean squared error out of our predictions, but rather figuring out a reliable way to operationalize what already works pretty well into complex and ill-defined workflows. We can invest in more data hardware and develop ever more sophisticated algorithms, but if we don’t remember where the data are coming from and what processes our efforts are driving, we’re not meeting our industry’s mission to provide more comprehensive, more available, and more affordable care.
A version of this article first appeared in CIOReview.
